Redis的一些痛点
![图片[1]-云原生内存数据库Tair关键能力-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-245.png "云原生内存数据库Tair关键能力")
我们可以看一下左边跟右边的痛点为什么会是这样的情况?
其实总结下来就是开源的 Redis 在超多访问链接下,它的性能会下降。但是在容器化的时代下,应用的服务器变得越来越多,每一台应用它的访问连接数也会越来越多,几千上万是很常见的。
另外,在延时&抖动上, Redis 其实是一个单线程的,那在这种情况下,它只要有一个慢查询,譬如 Hgetall 之类的,它往往会带来整体变慢,其他的短查询也得不到很好地处理。
HA 高可用会出现误判,跟前面一样,一个 Hgetall比较大的情况下,处理线程会把CPU 全占住, HA 的判活就有可能得不到处理,所以它的整个数据操作与控制操作都是在一个工作线程内处理的。还有整体的内存统计是没有区分开的,所以用户往往发现配了实例内存,还没有用满的情况下就发生了数据淘汰。
然后,我们从内核的技术上来讲一下 Redis 与 Tair 的一个区别。
Redis vs Tair
![图片[2]-云原生内存数据库Tair关键能力-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-247.png "云原生内存数据库Tair关键能力")
上图左边是开源的 Redis 在6.0之前,它是一个单线程的。在 6.0 之后,它号称是一个多线程的,但是从右图也能够看到,它只是在 IO 处理这块搞成多线程了,但是在内部真正的数据操作这一块,它依然是单线程在做。
为什么它很难做成多线程呢?一是因为在原来的 Redis 内部,所有都是单线程的,大部分操作是没有锁的,所以想改成多线程是非常困难的;二是代码是在10年前写的,并没有进行重构过,在历史代码上去做优化是相对困难的。
对于Tair来说,我们脱离Redis,从头自研,我们把网络接收线程跟工作处理线程独立开了,都可以用 N x M 的方式灵活地去配;这样 Tair 就可以处理数十万的活跃的连接数,因为网络线程足够多,单机的处理引擎可以提升得足够高,甚至可以跑到百万级。
在业内也有一种讨论,到底是搞成分布式好还是搞成单机好?
在我看来,非常多情况下,单机的形态会有不少优势。如今业务越来越复杂,如果把它搞成分布式,往往会有一些跨节点的计算,甚至要求这些计算要有事务。搞成集群后,跨节点的计算和事务会变得越来越复杂,很难去处理。在这种情况下,能够给客户一个大规格、大访问处理量的单机引擎其实是最合适的。
当然,在多线程内部我们也做了一些慢查询请求,把它实时监测出来,并且分离到慢查询请求池里面。这一类的工作,我们尽量确保用户的请求能够在一个比较确定的访问延时里面返回给用户。
接下来我们看看Tair引擎的高可用,前面我们讲了社区版的 Redis ,它的探活跟数据操作其实是在一个工作线程里面,因为数据操作慢了之后,会产生一些误判,所以我们把所有的管控请求放到独立的处理系统里面;就把这些 HA 把这些访问、统计信息等完全隔离,包括用户的数据访问跟系统的高可用统计都是隔离开的,确保质量更好。
![图片[3]-云原生内存数据库Tair关键能力-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-250.png "云原生内存数据库Tair关键能力")
接下来我们讲讲Tair的集群架构。
Tair的集群架构
![图片[4]-云原生内存数据库Tair关键能力-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-253.png "云原生内存数据库Tair关键能力")
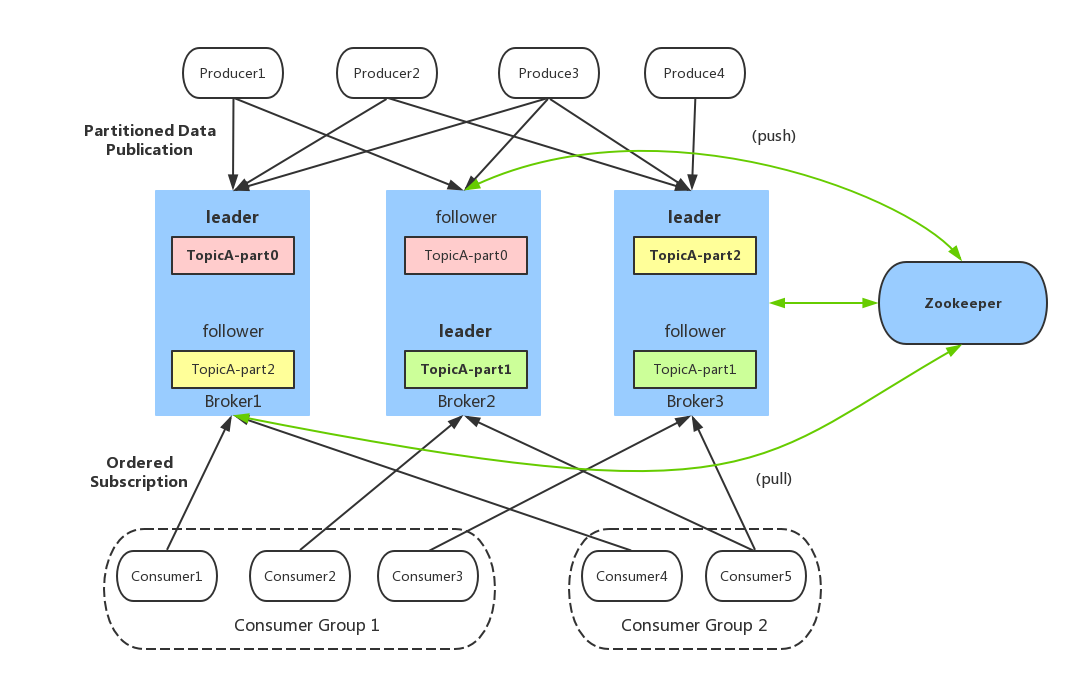
Tair的集群架构,包括搬迁的扩缩容,与开源的社区版是完全不一样的。开源的社区都是用 Gossip ,相当于是P2P 来做信息的同步与探活。另外它的节点变得越来越多的时候,想在集群里面达到信息的一致性也会变得越来越慢。社区版的迁移扩缩容是按 Key 级别的,所以在大 Key 的时候往往会出现一些迁移卡顿等,这个时候也会有一些 HA 的误判。我们如今在这一方面也做了一些改进,相当于是由中心节点对整个集群做 HA 的判活,包括集群管理。整个数据搬迁是按slot去搬迁的,所以整个搬迁速度会比按key快很多。
特定重要场景的优化
![图片[5]-云原生内存数据库Tair关键能力-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-257.png "云原生内存数据库Tair关键能力")
Pubsub相当于是 Tair 与 Redis 里面做消息处理用的。原来的单线程,如果是挂载的客户端多的话,其实推送起来会比较慢。它的单线处理,相当于在Tair 里面把它作为一个多线程处理,所以这是一个并发的处理操作。
TairStack:丰富的数据模型
![图片[6]-云原生内存数据库Tair关键能力-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-260.png "云原生内存数据库Tair关键能力")
TairStack有着丰富的数据模型,这其实是在阿里内部实践中积累出的常用数据结构,目的就是让业务开发更容易。从上图可以看到,我们有些是对外开源了,包括:TairHash、TairString等,这些结构也是可以放到开源的 Redis 里面去用,跟开源的 Redis 是完全兼容的,这些module在公共云上也被非常多客户使用了。
接下来我们看看Tair的企业级能力。
Tair的企业级能力
![图片[7]-云原生内存数据库Tair关键能力-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-243.png "云原生内存数据库Tair关键能力")
Tair的企业级能力这里我主要讲3部分,包括全球多活、安全能力和 Tair引擎可观测性。
- 全球多活
如今的一些客户,特别是中大型的客户,他希望在多个地域做多活。所以我们今天是可以做到三地域多活的同步。它的原理是通过 Binlog 来做 3地的多活。我们更建议应用在做多活的时候,能够在应用层面按 key 分布到多个单元,这样会更容易避免冲突。
- 安全能力
安全能力部分在公有云上也是比较重要的一个地方。我们提供给客户的实例是在VPC内部,整个安全网络上面是有确保的,客户可以通过 SSL来加密访问Tair,这个上面可以进行更高层次的访问通信的加密。
我们有一个功能叫 PITR,可以帮助客户把数据恢复到客户指定的任意时间点,可以到秒级别。还有一个重要的功能就是用户的审计。经常会有一些客户说,我的访问量怎么这么大?这个访问源是从哪里过来的?或者是我的数据被清理掉了,是哪里被删的,通过这个是能够看得到的。所以从整个技术实现上来说,我们其实做了一些高频的快照,大家可以认为是一个全量的快照,再加上增量的 Binlog 来帮助客户恢复到那个时间点去。
- Tair引擎可观测性
在可观测性上我们投入的也比较多,当然还是有一些没有做得特别好,譬如集群级别的聚合工作其实一直在探索。我们能够把有热 Key 的、有访问量比较大 key 的实时地看到,包括在引擎级别,每一个操作的访问延时是能够看得到的。一旦慢了的话,我们可以看到在哪一块操作上慢了。