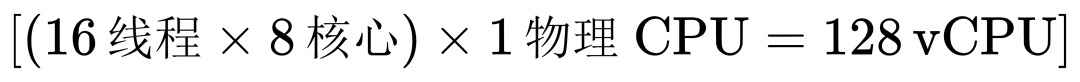1. Kubernetes的由来
Kubernetes的名字来自希腊,意思是“舵手”或“领航员”。简称K8S,是用8代替名字中间的8个字符“ubernete”而成的缩写。所以,我们说K8S也就是说Kubernetes。在行业内,我们更习惯说K8S,而不是Kubernetes。
Google公司在10多年前开始采用的容器化基础架构——borg。随着Docker的大规模应用,Google采用Go语言对Borg框架进行了重写,开发出了Kubernetes。Google 于 2014 年开源了 Kubernetes 项目。
2015年4月,Borg论文《Large-scale cluster management at Google with Borg》伴随Kubernetes的高调宣传被Google首次公开,人们终于有缘得窥其全貌。
在Google内部,Kubernetes的原始代号曾经是Serven of Nine,即星际迷航中友好的“Borg”角色,它标识中的舵轮有七个轮辐就是对该项目代号的致意,如图所示。
![图片[1]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-37.png "Docker和K8S架构和实践详解")
Kubernetes v1.0于2015年7月21日发布,紧随其后,Google与Linux基金会合作组建了Cloud Native Computing Foundation(云原生计算基金会,简称为CNCF),并将Kubernetes作为种子技术予以提供。这之后,Kubernetes进入了版本快速迭代期,从此不断地融入着新功能,如Federation、Network Policy API、RBAC、CRD和CSI,等等,并增加了对Windows系统的支持。
那K8S到底是做什么的呢?在说它之前我们少不了要对Docker进行一番概述
2. 什么是Docker
![图片[2]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-44.png "Docker和K8S架构和实践详解")
Docker 公司的前身是 DotCloud,2010年成立,2013年更名 Docker,同年发布了 Docker-compose 组件提供容器的编排工具。2014年 Docker 发布1.0版本,2015年Docker 提供 Docker-machine,支持 windows 平台。
Docker基于Go 语言开发并遵从 Apache2.0 协议开源。Docker 从 17.03 版本之后分为 CE(Community Edition: 社区版) 和 EE(Enterprise Edition: 企业版)
那到底什么是Docker?
Docker是一个C/S架构的系统,Docker守护进程运行在主机上, 然后通过Socket连接从客户端访问Docker守护进程。Docker守护进程从客户端接受命令,并按照命令,管理运行在主机上的容器。
一个Docker是一个运行时的环境,简单理解为进程运行的集装箱。
Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。Docker容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。
2.1 Docker VS KVM
Docker有着比虚拟机更少的抽象层。Docker利用的是宿主机的内核,VM需要的是Guest OS,分层架构如下:
![图片[3]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-38.png "Docker和K8S架构和实践详解")
二者的架构不同:
- VM在宿主机操作系统的基础上创建虚拟层、虚拟化的操作系统和虚拟化的仓库,然后再安装应用;
- Container(Docker容器),在宿主机的操作系统上创建Docker引擎,在引擎的基础上再安装应用。
作为一种轻量级的虚拟化方式,Docker在运行应用上跟传统的虚拟机方式相比具有显著优势:
- Docker 容器很快,启动和停止可以在秒级实现。
- Docker 容器对系统资源需求很少,一台主机上可以同时运行数千个Docker容器。
- Docker 通过类似Git的操作来方便用户获取、分发和更新应用镜像。
- Docker 通过Dockerfile配置文件来支持灵活的自动化创建和部署机制,提高工作效率。
- Docker 容器除了运行其中的应用之外,基本不消耗额外的系统资源,保证应用性能的同时,尽量减小系统开销。
- Docker 利用Linux系统上的多种防护机制实现了严格可靠的隔离。从1.3版本开始,Docker引入了安全选项和镜像签名机制,极大地提高了使用Docker的安全性。
| 特性 | 容器 | 虚拟机 |
| 启动速度 | 秒级 | 分钟级 |
| 硬盘使用 | 一般为MB | 一般为GB |
| 性能 | 接近原生 | 弱于原生 |
| 系统支持量 | 单机支持上千个容器 | 一般几十个 |
2.2 Docker 架构
Docker 包括三个基本概念:
- 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
- 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
3. Kubernetes架构
Docker不具备自动扩容、负载均衡以及分布式集群部署的能力。Kubernetes是容器集群的编排系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。它是基于容器(通常是Docker)之上的。
K8S是一个编排容器的工具,其实也是管理应用的全生命周期的一个工具,从创建应用,应用的部署,应用提供服务,扩容缩容应用,应用更新,都非常的方便,而且可以做到故障自愈。
我们从整体架构来入手,来看看K8s架构。
![图片[4]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-39.png "Docker和K8S架构和实践详解")
3.1 组件
一个K8S集群包含一个master节点和一群node节点
- Mater节点负责管理和控制
- Node节点是工作负载节点,里面是具体的容器,容器中部署的是具体的服务。
3.1.1 Master
用于控制 Kubernetes 节点的计算机。所有任务分配都来自于此。Mater节点包括API Server、Scheduler、Controller Manager、etcd。
- API Server:整个集群的对外接口,供客户端和其他组件调用。
- Scheduler:负责集群内部资源调度
- Controller Manager:负责管理控制器。
- etcd:用于保存集群中所有网络配置和对象状态信息。
下面详细介绍下master组件
1、API Server
API Server是整个集群的统一入口,各组件的协调者,以HTTP的API形式对外提供服务,所有对象资源的增删改查和监听操作都交给API Server处理后再提交给etcd进行存储。
2、Scheduler
Scheduler负责集群内部资源调度,根据调度算法为新创建的pod选择一个node节点,Scheduler在整个集群中起到了承上启下的重要功能,承上是指负责接收Controller Manager创建的新的pod,为其安排一个node节点,启下是指当为pod选定node节点后,目标Node上的kubelet服务进程会接管该pod。
![图片[5]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-40.png "Docker和K8S架构和实践详解")
简单描述下创建Pod的流程:
- 通过kubectl发送创建pod的请求,命令会先被apiserver拦截,再把创建的pod存储到etcd的podQueue中
- Scheduler发起调用请求,命令被apiserver拦截,获取etcd中podQueue.NodeList,使用调度算法(调度算法:预选调度、优选策略)选择一个合适的node节点
- 把确定了的合适的pod、node存储到etcd中
- node节点上的Kubelet进程发送请求获取pod、node对应创建资源
- node发现pod是本node需要创建的,kubelet就开始创建pod
3、Controller Manager
每个资源都对应一个控制器(Kubernets Controller),用来处理集群中常规的后台任务,而Controller Manager是用来负责管理控制器的。
K8S集群有以下控制器:
- Replication/ReplicationSet Controller:保证RC中定义的副本数量与实际运行的pod数量一致。
- Node Controller:管理维护Node,定期检查Node节点的健康状态,标识出失效和未失效的Node节点。
- Namespace Controller:管理维护Namespace,定期清理无效的Namespace,包括Namespace下的API对象,例如pod和service等
- Service Controller:管理维护Service,提供负载以及服务代理。
- Endpoints Controller:管理维护Endpoints,即维护关联service和pod的对应关系,其对应关系通过Label来进行关联的
- Service Account Controller:管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。
- Persistent Volume Controller:持久化数据控制器,用来部署有状态服务
- Deamon Set Controller:让每一个Node节点都运行相同的服务
- Deployment Controller:无状态服务部署控制器
- StateFulSet Controller:有状态服务部署控制器
- Job Controller:管理维护Job,为Job创建一次性任务Pod,保证完成Job指定完成的任务数目。
- Pod Autoscaler Controller:实现pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行pod的伸缩动作。
4、etcd
etcd是一个第三方的服务,提供分布式键值对存储,用于保存网络配置、集群状态等信息。K8S中有两个服务需要用到etcd来协调和存储数据:网络插件flannel和K8S本身状态,其中flannel使用etcd存储网络配置信息,K8S本身使用etcd存储各种对象的状态和元信息配置。
3.1.2 Node
node节点包括Docker、kubelet、kube-proxy、Fluentd、kube-dns(可选)、pod
![图片[6]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-41.png "Docker和K8S架构和实践详解")
1、kubelet
kubelet是Mater在Node节点上的代理,每个Node节点都会启动一个kubelet进程,用来处理Mater节点下发到Node节点的任务,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点的状态等工作,kubelet将每个pod转换成一组容器。
kubelet默认监听四个端口:4194、10250、10255、10248
- 4194端口:kubelet通过该端口可以获取到该节点的环境信息以及node上运行的容器状态等内容,访问 http://localhost:4194 可以看到 cAdvisor 的管理界面,通过 kubelet 的启动参 数 –cadvisor-port 可以指定启动的端口。
- 10250端口:kubelet API的端口,也就是kubelet server与api server的通讯端口,定期请求apiserver获取自己所应当处理的任务,通过该端口可以访问和获取node资源及状态。
- 10248端口:健康检查的端口,通过访问该端口可以判断kubelet是否正常工作,可以通过 kubelet 的启动 参数 –healthz-port 和 –healthz-bind-address 来指定监听的地址和端口
- 10255端口:提供了pod和node的信息,接口以只读形式暴露出去,访问该端口不需要认证和鉴权。
2、kube-proxy
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作,kube-proxy本质上类似于一个反向代理,我们可以把每个节点上运行的kube-proxy看作是service的透明代理兼LB。
kube-proxy监听apiserver中service与endpoints的信息,配置iptables规则,请求通过iptables直接转发给pod。
![图片[7]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-42.png "Docker和K8S架构和实践详解")
3、docker
运行容器的引擎,pod内部运行的都是容器,这个容器是由Docker引擎创建的,Docker引擎是node节点的基础服务。
4、pod
pod是最小的部署单元,一个pod由一个或多个容器组成,pod中共享存储和网络,在同一个Docker主机上运行。pod内部可以运行一个或多个容器,一般情况下,为了便于管理,一个pod下只运行一个容器。常用于sidercar服务部署。
3.1.3 Pod
pod:负责执行请求和所分配任务的计算机。由 Kubernetes 主机负责对节点进行控制,被部署在单个节点上的,且包含一个或多个容器的容器组。同一容器集中的所有容器共享同一个 IP 地址、IPC、主机名称及其它资源。容器集会将网络和存储从底层容器中抽象出来。
pod是一个大的容器,由K8S创建,pod内部的是docker容器,由Docker引擎创建。K8S不会直接管理容器,而是管理Pod。pod内部封装了docker容器,同时拥有自己的ip地址,也有用自己的HostName,Pod就像一个物理机一样,实际上Pod就是一个虚拟化的容器(进程),pod中运行的是一个或者多个容器。
![图片[8]-Docker和K8S架构和实践详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-344-43.png "Docker和K8S架构和实践详解")
pod的作用是管理线上运行的应用程序,在通常情况下,在服务上线部署的时候,pod通常被用来部署一组相关的服务。而一个调用链上的服务就叫做一组相关的服务。但是实际生产上一般是一个Pod对应一个服务,不会在一个Pod上部署太多的服务。
K8S中的pause容器主要为每个业务容器提供以下功能,从而对各个Pod进行了隔离:
- PID命名空间隔离:pod中不同的应用程序可以看到其他应用程序的进程ID
- 网络命名空间隔离:Pod中多个容器能够访问同一个IP和端口范围
- IPC命名空间隔离:Pod中多个容器能够使用System VIPC或POSIX消息队列进行通信
- UTS命名空间隔离:pod中多个容器共享一个主机名和挂在卷
- Pod中各个容器可以访问在Pod级别定义的Volumes
一个Pod创建的过程:首先kubelet会先创建一个pod,然后立马会创建一个pause容器,pause容器是默认创建的,然后再创建内部其他的业务容器。
3.1.4复制控制器(Replication controller)
用于控制应在集群某处运行的完全相同的容器集副本数量。
3.1.5 服务(Service)
将工作内容与容器集分离。Kubernetes 服务代理会自动将服务请求分发到正确的容器集——无论这个容器集会移到集群中的哪个位置,甚至可以被替换掉。
3.1.6 Kubelet
运行在节点上的服务,可读取容器清单(container manifest),确保指定的容器启动并运行。
3.1.7 kubectl
Kubernetes 的命令行配置工具。
3.2 控制器实例
kubernetes中建立了很多的controller(控制器),这相当于一个控制机,来管理pod的状态和行为。
Pod分为自主式Pod和控制器管理的Pod。类型:
- ReplicationController和ReplicaSet(无状态服务RS-Deployment)
- Deployment 无状态负载
- DaemonSet 守护进程集(以Node为节点部署)
- StateFulSet 有状态负载(有状态服务)
- Job/cronJob 普通任务/计划任务(批处理任务部署)
- Horizontal Pod Autoscaling 自动扩展(根据利用率平滑扩,可以理解为并不是一个控制器,而是一个控制器的附属品,以其他控制器作为模板)
3.2.1 ReplicationController(RC)
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。在新版本的Kubernetes 中建议使用ReplicaSet来取代ReplicationControlle,如果集群的资源不够,会动态的显示可用的pod。
ReplicaSet(RS)
ReplicaSet跟ReplicationController只是名字不一样,并且ReplicaSet支持集合式的selector,通过标签(matchLabels)来管理 Pod。虽然ReplicaSet 可以独立使用,但一般还是建议使用Deployment 来自动管理ReplicaSet,避免不兼容问题(比如ReplicaSet不支持rolling update但Deployment 支持)。
基本的yaml配置:
apiVersion: apps/v1 #api版本定义
kind: ReplicaSet #定义资源类型为ReplicaSet
metadata: #元数据定义
name: test
namespace: default
spec: # ReplicaSet的规格定义
replicas: 3 #定义副本数量为3个
selector: #标签选择器,定义匹配Pod的标签
matchLabels: # RS通过labels来确定某个Pod是否归该RS管,即RS通过标签来监控Pod
tier: test
template: #Pod的模板定义,与上面Pod的定义一致
metadata: #Pod的元数据定义
name: app-pod #自定义Pod的名称
labels: #定义Pod的标签,需要和上面的标签选择器内匹配规则中定义的标签一致,可以多出其他标签
tier: test
spec: #Pod的规格定义
containers: #容器定义
- name: nginx #容器名称
image: hub.org/library/nginx:v1 #容器镜像
imagePullPolicy: IfNotPresent #拉取镜像的规则
env:
- name: GET_HOSTS_FROM
value: dns
ports: #暴露端口
- name: http #端口名称
containerPort: 80创建并查看RS:
# 创建 RS
[root@k8s-master01 yaml]# kubectl create -f rs.yaml
# 查看创建的 rs
[root@k8s-master01 yaml]# kubectl get rs
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 25m
# 查看rs创建的 3 个 Pod,
[root@k8s-master01 yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-cbhjc 1/1 Running 0 25m
frontend-dffcd 1/1 Running 0 25m
frontend-qmugq 1/1 Running 0 25m
# 删除 Pod后,RS会自动重建 Pod,维持设置的副本数(3),通过 Pod 后的随机值可以看出,Pod是重新创建的
[root@k8s-master01 yaml]# kubectl delete pod --all
pod "frontend-cbhjc" deleted
pod "frontend-dffcd" deleted
pod "frontend-qmugq" deleted
[root@k8s-master01 yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-5lgj9 1/1 Running 0 19s
frontend-gxhrv 1/1 Running 0 19s
frontend-rwhc5 1/1 Running 0 19s修改pod的labels:
# 查看Pod的标签
[root@k8s-master01 yaml]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend-5lgj9 1/1 Running 0 9m20s tier=test
frontend-gxhrv 1/1 Running 0 9m20s tier=test
frontend-rwhc5 1/1 Running 0 9m20s tier=test
# 修改其中一个Pod的标签
[root@k8s-master01 yaml]# kubectl label pod frontend-5lgj9 tier=new --overwrite=true
pod/frontend-5lgj9 labeled
# RS会通过匹配 labels 来确定哪些 Pod 是自己管理的
# 当改变了 frontend-5lgj9 的 labels 时,该 Pod 已经不归 frontend 这个 RS 管了,所以 RS 又重新创建了一个Pod
[root@k8s-master01 yaml]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend-5lgj9 1/1 Running 0 84m tier=test
frontend-7fbp8 1/1 Running 0 4s tier=new
frontend-gxhrv 1/1 Running 0 84m tier=test
frontend-rwhc5 1/1 Running 0 84m tier=test
# 删除RS,Pod也会被删除
[root@k8s-master01 yaml]# kubectl delete rs test
[root@k8s-master01 yaml]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend-5lgj9 1/1 Running 0 98m tier=new3.2.2 Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 (declarative) 方法,用来替代以前的 ReplicationController 来方便的管理应用。典型的应用场景包括:
- 定义 Deployment 来创建 ReplicaSet和Pod
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续 Deployment
Deployment是通过管理RS来管理Pod的。
滚动更新:更新V1到V2,新建一个RS然后创建1个V2,删除1个V1:达到滚动更新,此时RS,停用、保留,可以回滚:
创建并查看
apiVersion: apps/v1 #api版本定义
kind: Deployment #定义资源类型为Deploymant
metadata: #元数据定义
name: nginx-test #deployment控制器名称
namespace: default #名称空间
spec: #deployment控制器的规格定义
replicas: 3 #定义deployment副本数量为2个
selector: #标签选择器,定义匹配Pod的标签
matchLabels:
app: nginx-test
template: #Pod的模板定义
metadata: #Pod的元数据定义
labels: #定义Pod的标签,和上面的标签选择器标签一致,可以多出其他标签
app: nginx-test
spec: #Pod的规格定义
containers: #容器定义
- name: nginx #容器名称
image: hub.org/library/nginx:v1 #容器镜像
ports: #暴露端口
- name: http #端口名称
containerPort: 80创建Deployment并查看:
# 创建Deployment对象
# --record 可以方便的查看 revision 的变化(roolout 被触发(spec.template被更改)就会创建一个 revision)
kubectl apply -f deployment.yaml --record
[root@k8s-master01 yaml]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 8m30s
[root@k8s-master01 yaml]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-645ccc47cc 3 3 3 9m32s
[root@k8s-master01 yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-645ccc47cc-885sz 1/1 Running 0 9m37s
nginx-deployment-645ccc47cc-k5jcm 1/1 Running 0 9m37s
nginx-deployment-645ccc47cc-rwnk5 1/1 Running 0 9m37s
kubectl get deployment 命令所显示的字段有:
- NAME:Deployment 的名称。
- READY:显示应用程序的可用的副本数。显示的模式是“就绪个数/期望个数”。
- UP-TO-DATE:显示为了达到期望状态已经更新的副本数。
- AVAILABLE:显示应用可供用户使用的副本数。
- AGE:显示应用程序正常运行的时间。
扩容
kubectl scale deployment nginx-test --replicas=5更新
修改 Pod 模板相关的配置参数便能完成 Deployment 控制器资源的更新。
更新容器的镜像:
kubectl set image deployment/[deployment名称] [容器名称]=[镜像名称]kubectl set image deployment/nginx-test nginx=myapp:v2
# 可以看到原来的 RS 已经停用并做为备份,并创建了新的 RS
[root@k8s-master01 yaml]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-645ccc47cc 0 0 0 4h45m
nginx-deployment-6c67f64d64 5 5 4 8s回滚
可以通过设置 .spec.revisonHistoryLimit 项来指定 deployment 最多保留多少 revision 历史记录。默认的会保留所有的 revision;如果将该项设置为 0,Deployment 就不允许回退了
# 回到上一个版本
kubectl rollout undo deployment/nginx-test
# 查看当前的更新状态
# 如果 rollout 成功完成, 该命令将返回一个 0 值的 Exit Code
kubectl rollout status deployments/nginx-test
# echo $? # 输出 0
# 查看当前版本(自定义 Pod 的输出)
kubectl get pods -o custom-columns=Name:metadata.name,Image:spec.containers[0].image
# 通过该命令查看更新历史记录,Pod 模板被修改就会创建一个 revision
kubectl rollout history deployment/nginx-test
# 查询结果,创建 Deployment 时加上 --record 才会显示CHANGE-CAUSE
# REVISION CHANGE-CAUSE
# 1 kubectl apply --filename=deployment.yaml --record=true
# 2 kubectl apply --filename=deployment.yaml --record=true
# 回滚到指定版本
kubectl rollout undo deployment/nginx-deployment --to-revision=1
# 暂停 deployment 的更新
kubectl rollout pause deployment/nginx-test更新策略
Deployment 可确保在更新时仅关闭一定数量的 Pod。默认情况下,它确保至少所需 Pods 75% 处于运行状态(最大不可用比例为 25%),这个参数可以自定义。
Deployment 还确保创建 Pod 数量只可能比期望 Pods 数高一点点。 默认情况下,它可确保启动的 Pod 个数比期望个数最多多出 25%(最大峰值 25%)。
如果旧的 Pod 创建还没有达到期望数时(如期望数是 5,但现在只创建了3个),就更新了 Pod。在这种情况下,Deployment 会立即杀掉已创建的旧 Pod,并开始创建新 Pod。它不会等到所有的旧 Pod 都创建完成后才开始创建新 Pod。
例如,如果仔细查看上述 Deployment (kubectl describe deployment),将看到它首先创建了一些新的 Pod,然后删除了一些旧的 Pods。并且创建新的 Pods 创建没有到达 25% ,它不会杀死老 Pods,直到有足够的数量新的 Pods 已经出现。 然后开始杀死老 Pods ,在足够数量的旧 Pods 被杀死前并没有创建新 Pods。它确保至少 4 个 Pod 可用,同时最多总共 7 个 Pod 可用。
3.2.3 Horizontal Pod Autoscaling(HPA)
HPA根据利用率平滑扩展,仅适用于Deployment 和ReplicaSet ,在V1版本中仅支持根据Pod的CPU利用率扩所容,在vlalpha 版本中,支持根据内存和用户自定义的metric扩缩容。
HPA基于RS定义,并且监控V2Pod的资源利用率:
当符合条件后,会创建Pod:
每次创建后判断条件,符合后继续创建,直到最大值。使用率小就回收,直到最小值,实现水平自动扩展(弹性伸缩)。
3.3.4 StatefulSet
StatefulSet是为了解决有状态服务的问题(对应Deployments 和Repl icaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度(比如删除后重新创建)后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName 和HostName 不变,基于Headless Service(即没有Cluster IP的Service )来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候**要依据定义的顺序依次依次进行(**即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running 和Ready状态),基于init containers来实现有序收缩,有序删除(即从N-1到0)
- 部署顺序和收缩顺序是相反的。
一个完整的 StatefulSet 应用由三个部分组成: headless service(无头服务)、StatefulSet controller、volumeClaimTemplate(PVC)。
- Headless Service:定义 Pod 网络标识( DNS domain);
- volumeClaimTemplates :存储卷申请模板,创建 PVC。指定 pvc 名称大小,将自动创建 pvc,且 pvc 必须由存储类供应;
- StatefulSet :定义具体应用,名为 APP,有三个 Pod 副本,并为每个 Pod 定义了一个域名部署 statefulset。
为什么需要 headless service 无头服务?
在用 Deployment 时,每一个 Pod 名称是没有顺序的,是随机字符串,因此是 Pod 名称是无序的,但是在 statefulset 中要求必须是有序 ,每一个 pod 不能被随意取代,pod 重建后 pod 名称还是一样的。而 pod IP 是变化的,所以是以 Pod 名称来识别。pod 名称是 pod 唯一性的标识符,必须持久稳定有效。这时候要用到无头服务,它可以给每个 Pod 一个唯一的名称 。
除此之外,StatefulSet 在 Headless Service 的基础上又为 StatefulSet 控制的每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为:
$(podname).(headless server name)
FQDN:$(podname).(headless server name).namespace.svc.cluster.local为什么需要 volumeClaimTemplate?
对于有状态的副本集都会用到持久存储,对于分布式系统来讲,它的最大特点是数据是不一样的,所以各个节点不能使用同一存储卷,每个节点有自已的专用存储,但是如果在 Deployment 中的 Pod template 里定义的存储卷,是所有副本集共用一个存储卷,数据是相同的,因为是基于模板来的;而 statefulset 中每个 Pod 都要自已的专有存储卷,所以 statefulset 的存储卷就不能再用 Pod 模板来创建了,于是 statefulSet 使用 volumeClaimTemplate,称为卷申请模板,它会为每个 Pod 生成不同的 pvc,并绑定 pv,从而实现各 pod 有专用存储。这就是为什么要用 volumeClaimTemplate 的原因。
# headless service
apiVersion: v1
kind: Service
metadata:
name: app
labels:
app: app
spec:
ports:
- port: 80
name: web
clusterIP: None # 通过指定 clusterIP 为 None 实现 headless service
selector:
app: nginx # (A) A,B,C 三处要相同,根据 label 来匹配哪些 pod 归无头服务管
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: app # (B) A,B,C 三处要相同,根据 label 匹配决定哪些 pod 归StatefulSet管
serviceName: "app" # 指定 Service 名称(上面创建的,一定要是个无头服务)
replicas: 3 # 副本数
template:
metadata:
labels:
app: nginx # (C) A,B,C 三处要相同,label标签
spec:
containers: # 容器信息
- name: nginx
image: docer/myapp:v2
ports:
- containerPort: 80 # 释放的端口
name: web # 端口名字
volumeMounts: # 挂载
- name: www
mountPath: /usr/share/nginx/html # 容器内目录
volumeClaimTemplates: # 卷请求声明模板(pvc模板)
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ] # 指定要请求的卷的访问模式
storageClassName: "nfs" # 指定要请求的卷的类名,只有与 PV 中的storageClassName 相同时,才会匹配
resources:
requests:
storage: 1Gi # 指定要请求的卷大小必须满足 1G在PVC中会详细介绍。
3.3.5 DaemonSet
DaemonSet确保全部(或者一些) Node上运行一个Pod的副本(同一个 Node 上运行多个 Pod 需要多个 DaemonSet)。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet 将会删除它创建的所有Pod。使用DaemonSet的–些典型用法:
- 运行集群存储daemon, 例如在每个Node上运行glusterd、 ceph;
- 在每个Node上运行日志收集daemon, 例如fluentd、 logstash;
- 在每个Node上运行监控daemon, 例如Prometheus Node Exporter。
apiVersion: apps/v1 #api版本定义
kind: DaemonSet #定义资源类型为DaemonSet
metadata: #元数据定义
name: daemonset-nginx #daemonset控制器名称
namespace: default #名称空间
labels: #设置daemonset的标签
app: daemonset
spec: #DaemonSet控制器的规格定义
selector: #指定匹配pod的标签
matchLabels: #指定匹配pod的标签
app: daemonset-APP #注意:这里需要和template中定义的标签一样
template: #Pod的模板定义
metadata: #Pod的元数据定义
name: app
labels: #定义Pod的标签,需要和上面的标签一致,可以多出其他标签
app: daemonset-app
spec: #Pod的规格定义
containers: #容器定义
- name: app-pod #容器名字
image: hub.org/library/nginx:v1 #容器镜像
ports: #暴露端口
- name: http #端口名称
containerPort: 80 #暴露的端口
可以看到两个节点上各运行一个:
[root@k8s-master01 yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
daemonset-nginx-js4tyu 1/1 Running 0 82s 10.244.1.21 k8s-node01 <none> <none>
daemonset-nginx-kkc5nb 1/1 R3.2.6 Job
job负责一次性的批处理任务,即仅执行一次的任务,他保证批处理任务的一个或者多个Pod成功结束。
随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。如 删除 Job ,会清除所创建的全部 Pod。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
apiVersion: batch/v1 # kubectl explain job 查看 job 版本
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["python","-Mbignum=bpi","-wle"print bpi(2000)"] # 通过 python 进行圆周率计算,输出小数点后2000位
restartPolicy: Never # 重启策略- spec.template 格式同 Pod
- 容器的 restartPolicy 仅支持 Never 或 OnFailure,因为 Job 就是批处理任务,执行完自动退出,如果是 Always,那么就会不断的执行
- 单个 Pod 时,默认 Pod 成功运行后(返回码为 0) Job 即结束
- spec.completions:标志Job结束需要成功运行的 Pod 个数,默认为 1
- spec.parallelism:标志并行运行的 Pod 的个数,默认为 1
- spec.activeDeadlineSeconds:标志失败 Pod 的重试最大时间,超过这个时间不会继续重试
Cronjob
Cronjob管理基于时间的Job,即在给定时间点运行一次或周期性地在给定时间点运行Job。
创建 Job 操作应该是幂等的。CronJob 仅负责创建与其调度时间相匹配的 Job,而 Job 又负责管理其代表的 Pod。
CronJob 的参数
- spec.schedule:调度指定任务运行周期,格式同 Cron,必填
- spec.jobTemplate:Job 模板指定需要运行的任务,格式同 Job,必填
- spec.startingDeadlineSeconds:启动 Job 的期限(秒级别),可选字段。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
- spec.concurrencyPolicy:并发策略,可选字段。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:Allow (默认):允许并发执行运行 Job;Forbid :禁止并发运行,如果前一个还没有完成,则直接跳过下一个,需配置;Replace :取消当前正在运行的 Job,用一个新的来替换,需配置。注意:当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
- spec.suspend:挂起,可选字段。如果设置为 true ,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为 false 。
- spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit:历史限制,可选字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为 3 和 1 。设置限制的值为 0 ,相关类型的 Job 完成后将不会被保留。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 16 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: go
image: ubox
args: # 运行命令,输出当前时间
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure [root@k8s-master01 yaml]# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
go */1 * * * * False 0 <none> 29s
[root@k8s-master01 yaml]# kubectl get job
NAME COMPLETIONS DURATION AGE
go-1603320660 1/1 108s 2m4s
go-1603320720 0/1 61s 61s
go-1603320780 0/1 34s 34s
# 删除 CronJob
kubectl delete deployment/nginx-test4. 高频操作
集群信息的各种查看基本上是在Master节点操作
1、 查看集群的配置信息
kubectl cluster-info2、查看 Node的状态
kubectl get nodes
kubectl get node [IP] //节点IP可以用空格隔开写多个
kubectl describe node [IP]
kubectl delete node [IP]3、查看 Service 基本信息
kubectl get service4、查看POD的状态
kubectl get pods --all-namespaces or kubectl get pods -A
kubectl get po --namespace=default
kubectl get po --namespace={default,kube-system}5、同时查看多种资源信息
kubectl get pod,svc -n kube-system6、查看资源类型所对应的Apiversion
kubectl explain pod7、查看字段帮助信息
kubectl explain deployment
kubectl explain deployment.spec
kubectl explain deployment.spec.replicas8、 查看一个Servcie 的pod配置和参数
kubectl get pod -l name=[service-name] -o wide
kubectl get rc
kubectl get cm
kubectl get rc [service-name] -o yaml
kubectl get cm [service-name] -o yaml9、锁定资源,不被调度
kubectl uncordon/cordon [node-ip]10、添加污点控制调度
kubectl taint node [node-ip] dedicate=standalone:NoSchedule //增加污点
kubectl taint node [node-ip] dedicate=standalone:NoSchedule- //删除污点:key=value:affect11、修改label,pod资源分割
kubectl label nodes [node-ip] type=[name] --overwrite