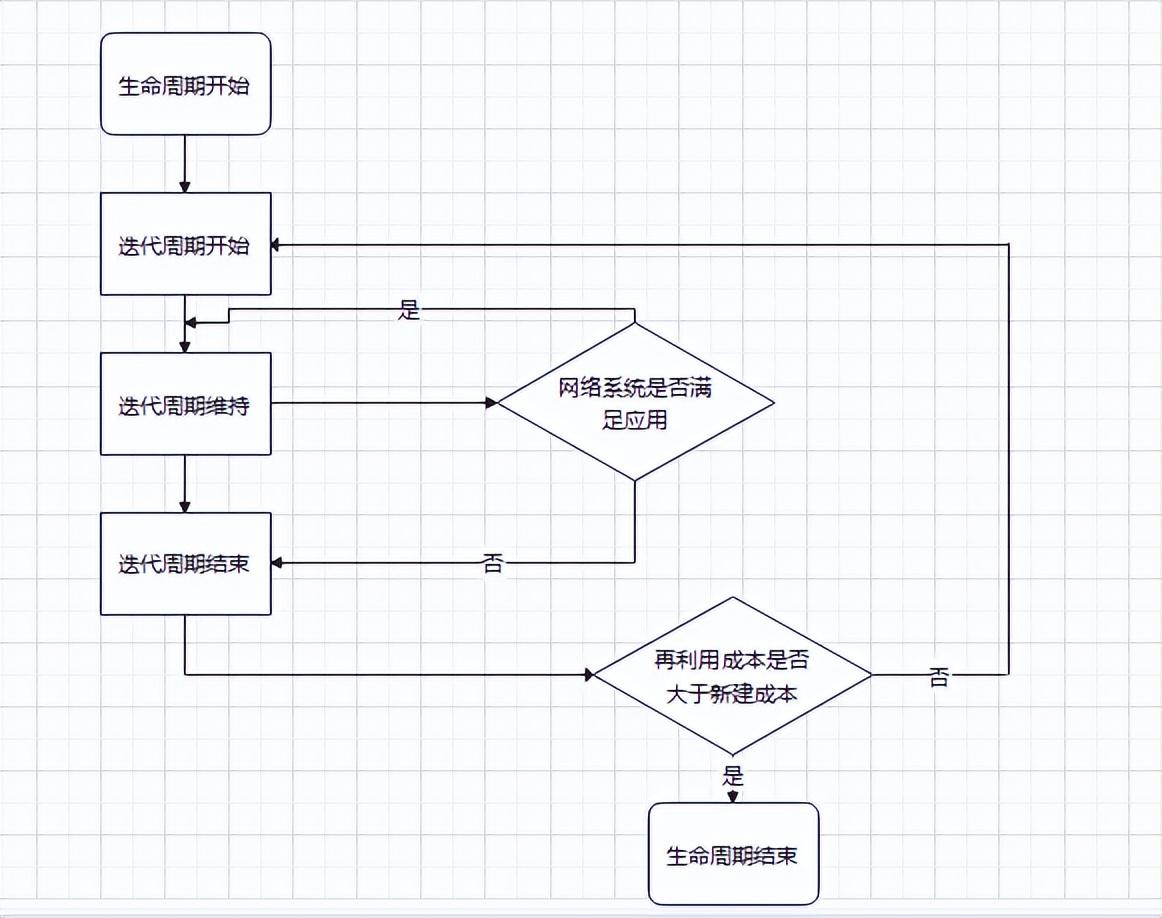
Paxos 是论证了一致性协议的可行性,但是论证的过程据说晦涩难懂,缺少必要的实现细节,而且工程实现难度比较高广为人知实现只有 zk 的实现 zab 协议。
Paxos协议的出现为分布式强一致性提供了很好的理论基础,但是Paxos协议理解起来较为困难,实现比较复杂。
然后斯坦福大学RamCloud项目中提出了易实现,易理解的分布式一致性复制协议 Raft。Java,C++,Go 等都有其对应的实现
之后出现的Raft相对要简洁很多。
引入主节点,通过竞选。
节点类型:Follower、Candidate 和 Leader
Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
基本名词
- 节点状态Leader(主节点):接受 client 更新请求,写入本地后,然后同步到其他副本中Follower(从节点):从 Leader 中接受更新请求,然后写入本地日志文件。对客户端提供读请求Candidate(候选节点):如果 follower 在一段时间内未收到 leader 心跳。则判断 leader 可能故障,发起选主提议。节点状态从 Follower 变为 Candidate 状态,直到选主结束
- termId:任期号,时间被划分成一个个任期,每次选举后都会产生一个新的 termId,一个任期内只有一个 leader。termId 相当于 paxos 的 proposalId。
- RequestVote:请求投票,candidate 在选举过程中发起,收到 quorum (多数派)响应后,成为 leader。
- AppendEntries:附加日志,leader 发送日志和心跳的机制
- election timeout:选举超时,如果 follower 在一段时间内没有收到任何消息(追加日志或者心跳),就是选举超时。
竞选阶段流程
① 下图表示一个分布式系统的最初阶段,此时只有 Follower,没有 Leader。Follower A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
![图片[1]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2.gif "分布式一致性协议之Raft协议详解")
② 此时 A 发送投票请求给其它所有节点。
![图片[2]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-1.gif "分布式一致性协议之Raft协议详解")
③ 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
![图片[3]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-2.gif "分布式一致性协议之Raft协议详解")
④ 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
![图片[4]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-3.gif "分布式一致性协议之Raft协议详解")
多个 Candidate 竞选
① 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票,例如下图中 Candidate B 和 Candidate D 都获得两票,因此需要重新开始投票。
![图片[5]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-4.gif "分布式一致性协议之Raft协议详解")
② 当重新开始投票时,由于每个节点设置的随机竞选超时时间不同,因此能下一次再次出现多个 Candidate 并获得同样票数的概率很低。
![图片[6]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-5.gif "分布式一致性协议之Raft协议详解")
日志复制
① 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。
![图片[7]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-6.gif "分布式一致性协议之Raft协议详解")
② Leader 会把修改复制到所有 Follower。
![图片[8]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-7.gif "分布式一致性协议之Raft协议详解")
③ Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
![图片[9]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-8.gif "分布式一致性协议之Raft协议详解")
④ 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
![图片[10]-分布式一致性协议之Raft协议详解-不念博客](https://www.bunian.cn/wp-content/uploads/2022/12/image-2-9.gif "分布式一致性协议之Raft协议详解")